

We're excited to announce Playbooks, a new capability in the Codd AI platform that lets you define, save, and execute structured sequences of agentic data analysis steps against your connected data sources through your governed corpus. Think of Playbooks as recipes for recurring analytical tasks: instead of asking the same series of questions every Monday morning, you define them once and run them on demand.
This post walks through what Playbooks are, why we built them, and how they work under the hood.
The Problem: Ad-Hoc Analysis Doesn't Scale
Teams using Codd's Canvas chat to explore data quickly develop recurring patterns: the same weekly KPI check, the same data quality validation before a release, the same series of queries to investigate an alert. Each time, someone manually re-asks the same questions, waits for results, and interprets them from scratch.
This works when you're exploring. It doesn't work when you need consistency, repeatability, and delegation.
Playbooks solve this by letting you capture those analytical patterns as first-class objects that anyone on the team can run.
The Trust Gap in AI-Driven Analytics
AI-powered analytics has changed how teams interact with data. Ask a question in natural language and instantly generate SQL, results, and insights.
But as organizations scale usage, a critical issue emerges:
The same question does not always produce the same analysis.
Ask: "How did revenue perform this week?"
On Monday, the AI breaks it down by region. On Wednesday, it focuses on product lines. A colleague phrases it differently and receives a different query path.
None of the answers are technically wrong.
But they are not operationally consistent.
When AI analysis is non-deterministic:
- Results cannot be reliably compared across time
- Methodology shifts silently
- Delegation becomes risky
- Institutional knowledge remains tribal
- Leadership confidence erodes
Conversational AI is powerful for exploration. Operational decision-making requires rigor.
Playbooks close that gap.
What Are Playbooks?
A Playbook is a structured, repeatable analytical workflow built on Codd AI's governed semantic foundation.
Each Playbook consists of ordered steps called plays, and each play defines:
- The exact SQL to execute
- The governed tables and metrics to use
- The business definitions applied
- The assessment criteria for interpretation
- The structured format of the output
The AI still performs reasoning, interpretation, and insight generation. But it does so within boundaries that you define and validate.
The result:
AI-powered analysis that is deterministic, auditable, and enterprise-ready.
Built on a Governed Semantic Layer
Unlike notebooks, dashboard schedulers, or generic AI copilots, Playbooks are not just saved queries.
They operate on Codd AI's contextual semantic layer, your governed business model.
That means:
- Standardized KPIs with enforced definitions
- Predefined relationships
- Role-based access controls
- Traceable metric lineage
- Policy enforcement at query time
You are not just freezing SQL.
You are operationalizing validated business logic.
This is how AI becomes Business-Fluent.
Chat vs. Playbooks
| Exploratory Chat | Playbooks | |
|---|---|---|
| SQL | Generated dynamically | Locked and validated |
| Tables | AI-selected | Governed and fixed |
| Metrics | Context inferred | Enterprise-defined |
| Assessment | Open-ended | Criteria-driven |
| Output | Varies by phrasing | Structured and repeatable |
| Reusability | Individual | Organization-ready |
Exploration is adaptive. Execution must be consistent.
Playbooks enforce that consistency.
Play Modes
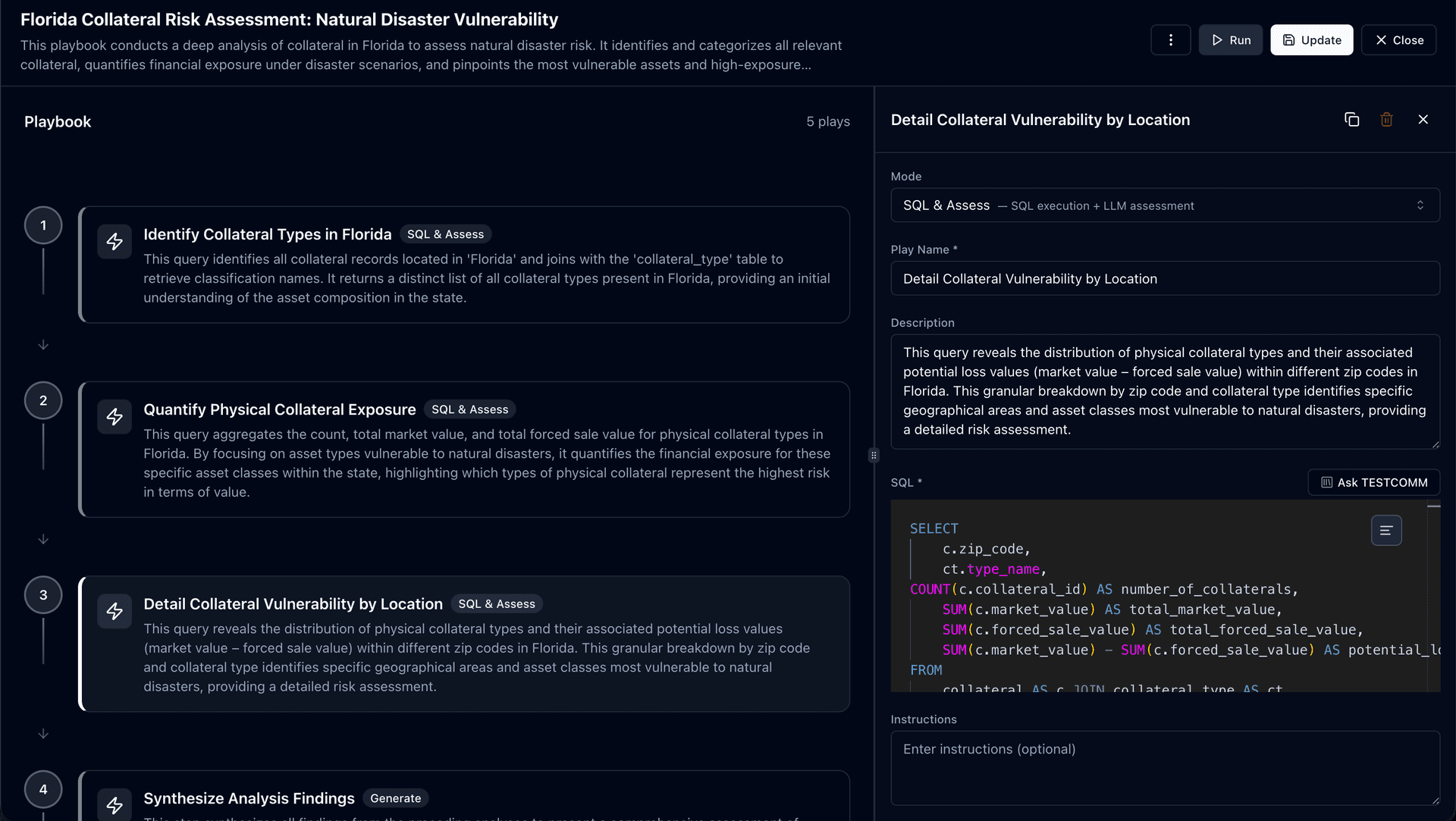
Each play supports a different level of determinism. To illustrate how they work together, consider a real-world example: Florida Collateral Risk Assessment, a Playbook that evaluates natural disaster vulnerability across collateral assets.
1. SQL
Fully deterministic. Same query. Same dataset. Every execution.
The SQL is locked and validated. No AI interpretation is applied to the results. You get raw data exactly as defined.
Best for: raw data extraction, control checks, metric snapshots.
Example: Play 1 in the collateral risk Playbook uses SQL mode to identify all collateral types in Florida. It joins with the collateral_type table to retrieve classification names, returning a distinct list of asset types present in the state. Every run produces the same foundational dataset.
2. SQL & Assess
Fixed query with structured AI evaluation.
The SQL is locked, but the AI evaluates the results against criteria you define:
- Thresholds and severity rules
- Categorization logic
- Comparison benchmarks
The AI applies them consistently across every execution.
Best for: KPI monitoring, performance analysis, anomaly detection.
Example: Plays 2 and 3 in the collateral risk Playbook use SQL & Assess mode. Play 2 aggregates count, total market value, and total forced sale value for physical collateral types vulnerable to natural disasters, then assesses which asset classes represent the highest financial exposure. Play 3 breaks down vulnerability by zip code, identifying specific geographical areas and asset classes most at risk. The AI evaluates severity and highlights concentrations, but the underlying queries and assessment criteria remain fixed.
3. Generate
AI-driven reasoning within strict instructions.
No fixed SQL, but tightly guided interpretation based on the outputs from prior plays.
Best for: executive summaries, synthesis, recommendations.
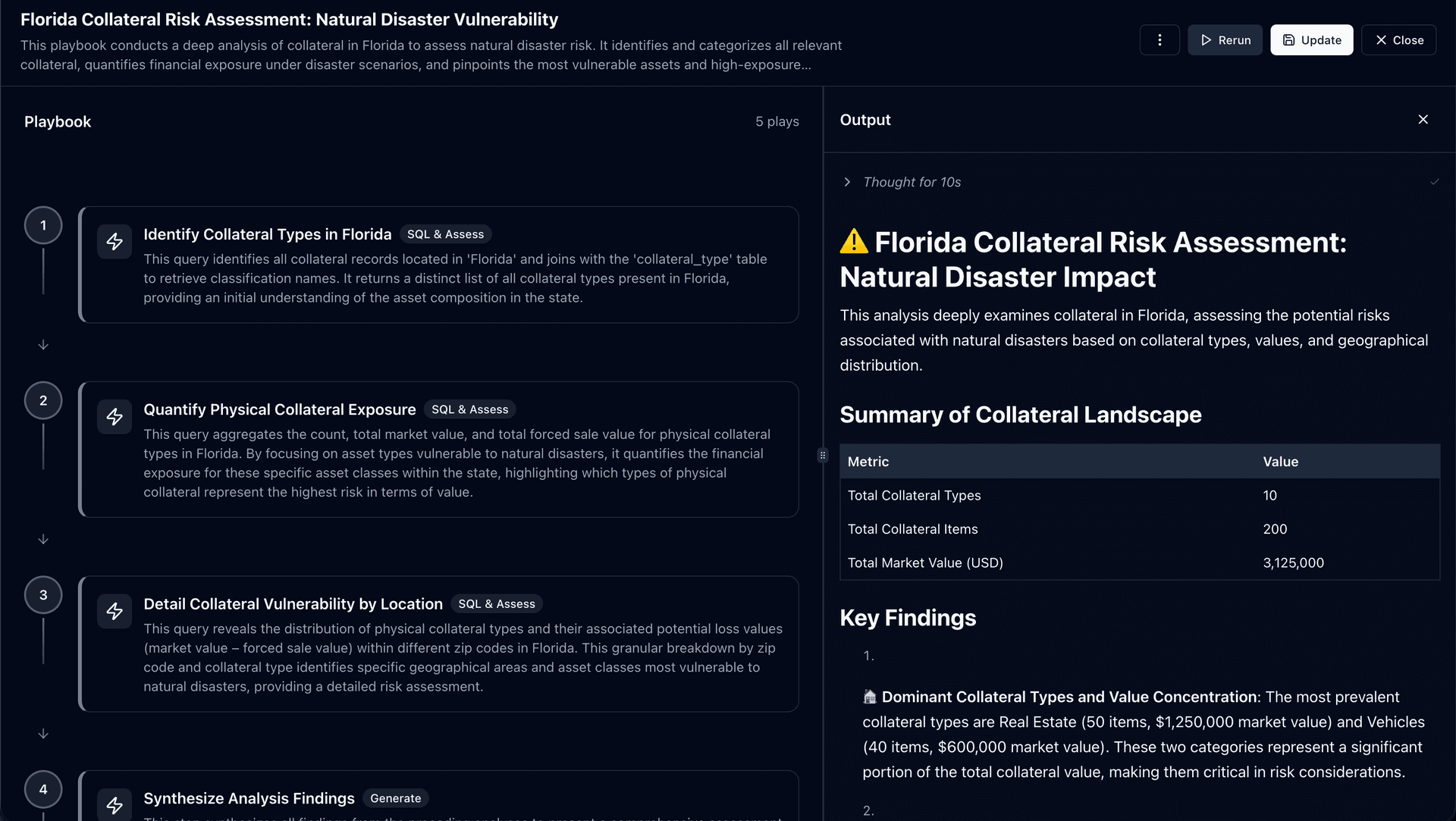
Example: Play 4 in the collateral risk Playbook uses Generate mode to synthesize all findings from the preceding plays into a comprehensive risk assessment. It produces structured output including a summary of the collateral landscape, key findings with severity ratings, and actionable recommendations. The AI reasons across the full analysis, but within the boundaries defined by the Playbook instructions.
How They Work Together
In the collateral risk example, the plays form a pipeline:
- SQL identifies the collateral landscape (deterministic foundation)
- SQL & Assess quantifies exposure and maps vulnerability (structured evaluation)
- SQL & Assess details location-level risk (granular assessment)
- Generate synthesizes findings into an executive-ready report (guided reasoning)
Most enterprise workflows rely on SQL & Assess to balance precision with insight, with a final Generate play to produce the summary.
Why Determinism Matters
1. Locked Logic
Queries are validated once and reused. No silent join changes. No missing filters. No shifting definitions.
2. Stable Interpretation
Assessment instructions remain fixed:
- "Flag drops greater than 5% week-over-week."
- "Compare against prior-year same period."
- "Categorize severity: Critical, Warning, Normal."
The AI does not invent new angles. It applies consistent business rules.
3. Reproducible Structure
Every run follows the same pipeline:
Step 1 → Step 2 → Step 3
This makes trend analysis meaningful because there is no methodology drift.
4. Full Auditability
Every execution captures:
- SQL executed
- Source tables used
- Data returned
- AI reasoning output
- Execution time
This is not debugging metadata.
It is an accountability record suitable for enterprise governance.
Playbooks vs. Dashboards
Dashboards display numbers.
Playbooks evaluate them.
| Dashboards | Playbooks | |
|---|---|---|
| Mode | Passive views | Active evaluation |
| Interpretation | Human interpretation required | Criteria-driven assessment |
| Metrics | Static metrics | Conditional logic |
| Reasoning | No embedded reasoning | AI-powered evaluation |
| Purpose | Reporting | Operational intelligence |
Dashboards answer: "What happened?"
Playbooks answer: "Does this require action?"
From Exploration to Institutional Knowledge
The typical workflow:
1. Explore in Canvas
Use conversational AI to test hypotheses and discover patterns.
2. Capture the Valid Analysis
Convert the working sequence into a Playbook.
3. Refine and Lock
Lock SQL. Clarify thresholds. Remove exploratory noise.
4. Operationalize
Run on-demand or embed inside automated workflows.
Now, any team member can execute the same trusted methodology.
This is how knowledge becomes scalable.
Integrating Playbooks into Actions
Playbooks integrate directly into Actions, Codd's visual workflow engine.
This enables:
- Scheduled recurring runs
- Conditional branching
- Slack or email notifications
- Approval workflows
- Automated remediation triggers
For example:
- Daily data quality Playbook executes at 6 AM
- If severity = Critical → Notify Slack
- If pass → Generate executive summary and distribute
Because Playbooks are deterministic, automation remains stable.
No unexpected output changes. No broken downstream logic.
Enterprise Use Cases
Weekly Business Review
Consistent revenue analysis with stable thresholds and executive-ready summaries.
Data Quality Validation
Pre-release validation with severity scoring and pass/fail classification.
Churn Monitoring
Standardized churn definitions with comparable monthly outputs.
Financial Close
Repeatable reconciliation checks with auditable logs.
Across all functions, the principle is identical:
Same definitions. Same methodology. Every run.
What's Coming Next
- Scheduled executions
- Parameterized inputs
- Execution history comparison
- Organization-wide Playbook libraries
Together, these extend Playbooks from repeatable workflows to enterprise operating systems for AI-driven analytics.
The Bottom Line
AI without structure creates variability. Variability undermines trust.
Exploration drives discovery. Determinism drives decisions.
Playbooks operationalize your governed semantic layer into repeatable, auditable, and automation-ready workflows. AI that leadership can depend on.
Want to learn more about how Playbooks can transform your team's analytical workflows? Schedule a demo to see Playbooks in action and explore how Codd AI can bring consistency, auditability, and trust to your data-driven decisions.